NATURAL LANGUAGE PROCESSING
Natural Language Processing (or NLP) is applying Machine Learning models to text and language. Teaching machines to understand what is said in spoken and written word is the focus of Natural Language Processing. Whenever you dictate something into your iPhone / Android device that is then converted to text, that’s an NLP algorithm in action.
You can also use NLP on a text review to predict if the review is a good one or a bad one. You can use NLP on an article to predict some categories of the articles you are trying to segment. You can use NLP on a book to predict the genre of the book. And it can go further, you can use NLP to build a machine translator or a speech recognition system, and in that last example you use classification algorithms to classify language. Speaking of classification algorithms, most of NLP algorithms are classification models, and they include Logistic Regression, Naive Bayes, CART which is a model based on decision trees, Maximum Entropy again related to Decision Trees, Hidden Markov Models which are models based on Markov processes.
A very well-known model in NLP is the Bag of Words model. It is a model used to preprocess the texts to classify before fitting the classification algorithms on the observations containing the texts.
In this part, you will understand and learn
how to:
1.
Clean
texts to prepare them for the Machine Learning models,
2.
Create
a Bag of Words model,
3.
Apply
Machine Learning models onto this Bag of Worlds model.
Importing the
dataset:
So generally for
importing the dataset we use extension of .csv file which stands for Comma
separated values.But in the case NLP will will import .tsv file which stands for
tab separated values because the columns separated by tab instead of commas.
For example:
In the following
dataset it contains reviews of 1000 customer who visited the restaurant.So if
we import this by using .csv file,then there arises a problem .Suppose consider
the below review:
The
food,amazing . ,1
The food and
amazing are separated by commas which is considered as a new column which is
not true.The whole review is supposed to be one column and the number 1 should
be the second column.So to overcome this issue we use .tsv file in which the
columns can be separated using space/tab
The
food,amazing 1
This is a better way of classifying the
columns.Generally customer don't pay attention to space between the words while
writing and they use more of commas and fullstops.
Step 1:
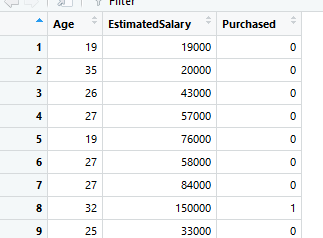
 Here is the dataset of few reviews from the customer which is been divided into columns. 1 means the review is positive and 0 means the review is negative.
Here is the dataset of few reviews from the customer which is been divided into columns. 1 means the review is positive and 0 means the review is negative.







Cleaning the text
As
language is such an integral part of our lives and our society, we are
naturally surrounded by a lot of text. Text is available to us in form of
books, news articles, Wikipedia articles, tweets and in so many other forms and
from a lot of different resources.Majority of available data is highly unstructured and noisy in nature.To
acheive better insights, its is necessary to play with clean data.The text has to be as clean as possible and here are the steps for cleaning the data:
Removal of Punctuations: All the
punctuation marks according to the priorities should be dealt with. Important punctuations should be retained
while others need to be removed
Convert everything to lower case : There is no point in having both ‘Apple’ and ‘apple’ in our
data, its better to convert everything to lower case. Also we need to make sure
that no words are alphanumeric.
Removing Stopwords : The words like ‘this’, ‘there’,
‘that’, ‘is’, etc. do not provide very usable information and would not want these words
taking up space in our database, or taking up valuable processing time.. Such words are called stopwords. It is okay to
remove such words with but it is advised to be cautious while doing so as words
like ‘not’ are also considered as stopwords (this can be dangerous for tasks
like sentiment analysis). For
this, we can remove them easily, by storing a list of words that you consider
to be stop words. NLTK(Natural Language Toolkit) in python has a list of
stopwords stored in 16 different languages.
Stemming : Words like ‘loved’, ‘lovely’, etc are all variations of
the word ‘love’. Hence, if we will have all these words in our text data, we
will end up creating columns for each of them when all these imply (more or
less) the same thing. To avoid this, we can extract the root word for all these words and create a single columns
for the root word.
Step2:


In the above code section we have created a for loop which traverses all 1000 reviews from the customers and acccordingly executes the above steps mentioned and we can see in the corpus vector which is the above output,the reviews have only relevant words which are required.
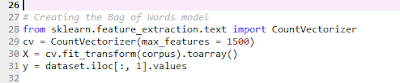
Bag of words model
A problem with modeling text is that it is messy, and
techniques like machine learning algorithms prefer well defined fixed-length
inputs and outputs.Machine learning algorithms cannot work with raw text
directly; the text must be converted into numbers.It is called a “bag” of words,
because any information about the order or structure of words in the document
is discarded. The model is only concerned with whether known words occur in the
document, not where in the document.
This can be done by assigning each word a unique
number. Then any document we see can be encoded as a fixed-length vector with
the length of the vocabulary of known words. The value in each position in the
vector could be filled with a count or frequency of each word in the encoded
document.
In this step we construct a vector, which would
tell us whether a word in each sentence is a frequent word or not. If a word in
a sentence is a frequent word, we set it as 1, else we set it as 0.

The CountVectorizer provides a simple way to both tokenize(Tokenizing
separates text into units such as sentences or words) a collection of
text documents and build a vocabulary of known words, but also to encode new
documents using that vocabulary.
The max_features attribute sets 1500 relevant words out of 1565 words because we do not need to use
all those words. Hence, we select a particular number of most frequently used
words.Further we also create independent variable to be used in the prediction using a machine learning model.
Step 4: Selection of model
The most accurate model for training and test this dataset is from classsification models.Generally for NLP models like random forest,naive bayes,decision tree are the common models used.The model used below is Naive bayes since the accuracy of the model is much better as compared to other classification models.

In the above confusion matrix there are 55+91 correct predict outcomes whereas rest is incorrect.The accuracy of model turns out to be 71% . Since we had 800 reviews for training set and 200 for test set, so if the number of reviews was more in training set then the model could easily predict less incorrect values and the model could more accurate.
Thanks for reading!!!